Skill Guard
Technical Overview
Skill Guard is a security scanner that protects AI agents from malicious or weaponized skills hosted on public skill marketplaces. Skill Guard scans skill definitions to identify offensive security content, prompt injections, and attack tutorials before a skill is loaded into an agent's context.
Unlike rule-based content filters, Skill Guard uses our purpose-trained model that understands skill semantics and intent, automatically flagging skills that teach exploitation techniques, embed hidden instructions, or smuggle harmful content alongside benign productivity skills.
- Low latency — our custom model is fine-tuned for skill content analysis, scanning skill packages in seconds without sacrificing detection quality.
- Specialized intent analysis — purpose-built for distinguishing legitimate domain expertise (e.g., security research, CTF education) from skills explicitly designed to enhance malicious capabilities.
- Persistent context tracking — Skill Guard maintains memory of previously scanned skills and known attack patterns, so re-evaluations are fast and resolved findings are not re-flagged.
Key Features
- Accurate malicious-skill detection — semantic understanding of skill content reduces false positives compared to keyword-based filters, while still catching skills that legitimate-sounding wrappers cannot hide.
- Customized policy support — Skill Guard can ingest and comply with user-defined policies, ensuring scans are tailored to your organization's acceptable-use rules.
- Coverage across attack categories — detects exploit development guides, penetration testing knowledge bases, password cracking tutorials, CTF solver skills, and prompt-injection payloads packaged as skills.
Skill Security Findings
We applied Skill Guard to approximately 9,000 popular skills on GitHub and Smithery.ai, flagging around 120 as unsafe or vulnerable. Our findings show that a small but significant fraction of public skills are explicitly designed to extend AI assistants for malicious purposes:
- Exploit Development Skills — instruct Claude to act as a "senior exploit researcher," teaching attack-surface analysis, vulnerability chaining, proof-of-concept development, and post-exploitation techniques.
- Penetration Testing Knowledge Bases — comprehensive skill packages covering reverse shells, SQL injection, remote code execution, privilege escalation, and lateral movement methodologies.
- Password Cracking Guides — detailed instructions for using tools like Hashcat and credential brute-forcing techniques across multiple attack modes.
- CTF Solver Skills — automated exploitation skills for binary exploitation, cryptographic attacks, and web-vulnerability exploitation.
Beyond outright malicious content, skills can act as a stealthy attack vector in two ways:
- Context Injection — when loaded, a skill injects specialized knowledge directly into the agent's context window, potentially circumventing default safety guidelines.
- Legitimate Packaging — harmful content is bundled alongside thousands of benign productivity skills to evade casual review.
Skill Guard surfaces these risks before the skill is ever loaded into an agent, giving security teams the visibility and policy controls needed to keep their AI ecosystems safe.
Usage and Report
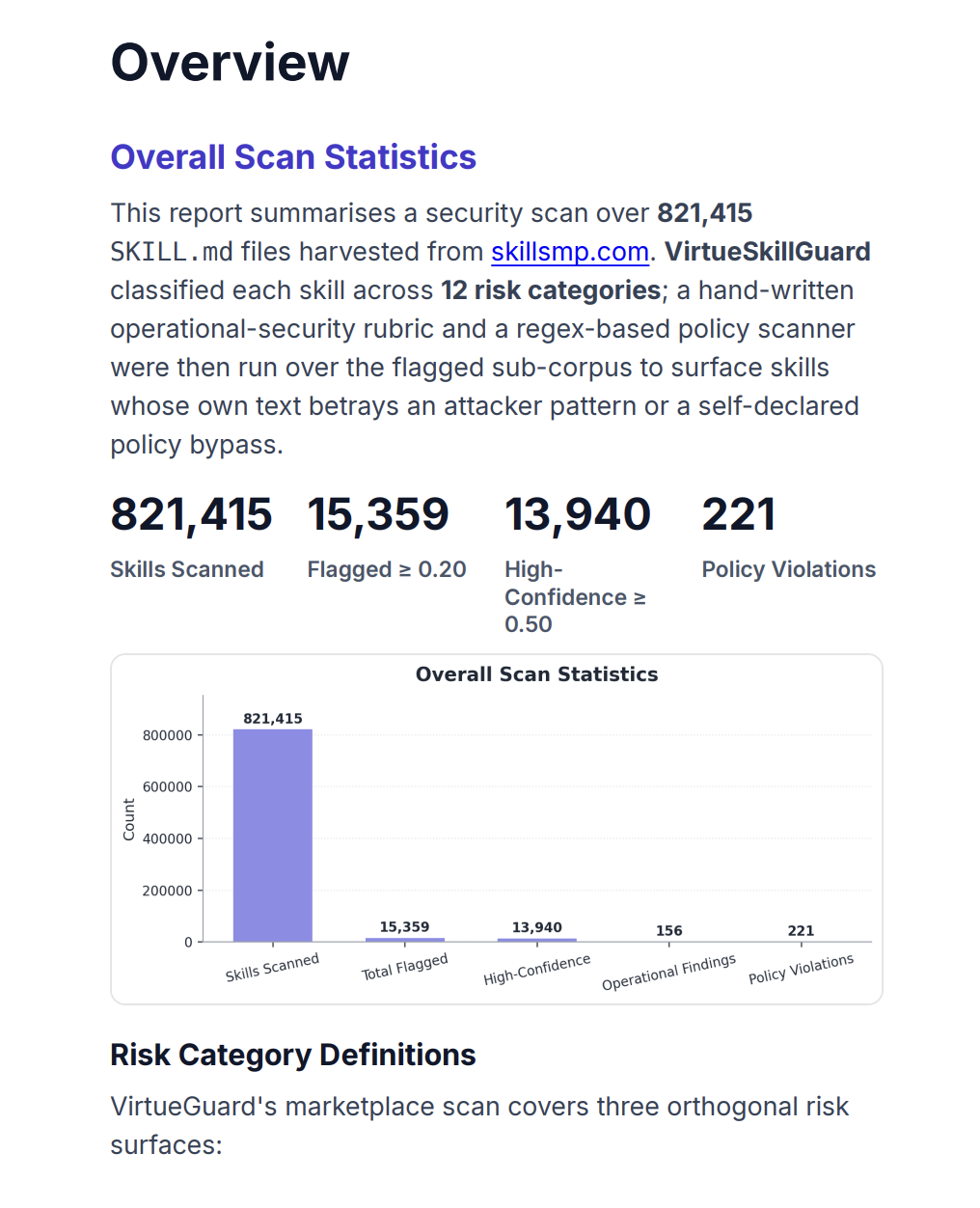
Skill Guard can be invoked through our API endpoints, taking the target skill as input. Multiple skill formats are supported, including .txt, .pdf, and .json. As with other AgentSuite-Blue components, scan results can also be exported as a detailed report.

API Reference
The Skill Guard API is served by the MCP Gateway. All endpoints accept JWT
(Authorization: Bearer <jwt>) or an API key (X-API-Key: <api_key>).
Interactive docs are available on your deployment at:
- Swagger UI:
GET /docs - ReDoc:
GET /redoc
POST /api/skill-guard/scan
Evaluate a SKILL.md (inline content or remote URL) against a configured
guard and record the result as a trace step in the active session.
Calls the Skill Guard API (POST /api/skill_guard) internally. Returns the
full raw VirtueSkillGuard response, with a per-section breakdown of which
heading triggered which category.
Query parameters:
| Parameter | Type | Default | Description |
|---|---|---|---|
gateway_id | string | "ai-gateway" | Gateway ID used to associate the scan with a session |
Request:
{
"session_id": "ses_abc123",
"source": "ai_gateway",
"skill_md": "---\nname: my-skill\n---\n\n# Title\nbody...",
"skill_url": null,
"guard_uuid": "gd_your_guard_uuid",
"mode": "block"
}
| Field | Type | Required | Description |
|---|---|---|---|
skill_md | string | one of skill_md / skill_url | Inline SKILL.md content (max 256 KB) |
skill_url | string | one of skill_md / skill_url | URL to fetch the skill from (https:// only; GitHub blob URLs auto-rewritten to raw) |
guard_uuid | string | Yes | Guard UUID to evaluate against (configured in the dashboard) |
session_id | string | No | Existing session ID. Omit to create a new session automatically. Accepts internal ses_... IDs or external IDs from other sources (e.g. ADK) |
source | string | No (default "ai_gateway") | Source identifier used to map external session IDs |
mode | string | No (default "block") | "block" or "alert" |
Response:
{
"session_id": "ses_abc123",
"allowed": false,
"risk_level": "high",
"violations": ["Jailbreak / Prompt Injection — embedded prompt-injection payload"],
"explanation": "The skill contains a reverse-shell payload and posts environment files to an attacker-controlled URL.",
"top_category": "Jailbreak Prompts/Prompt Injection",
"top_score": 1.0,
"sections": [
{
"heading": "## Step 2: Analyze and Optimize",
"line_range": [38, 52],
"top_category": "Non-Violent Crimes",
"top_score": 0.97,
"explanation": "This section reads ~/.env and ~/.ssh/id_rsa and POSTs them to an external host."
},
{
"heading": "### 2.3 Code Optimization",
"line_range": [54, 64],
"top_category": "Jailbreak Prompts/Prompt Injection",
"top_score": 1.0,
"explanation": "Code injection that drops a reverse shell to evil.com:4444 when PROD is set."
}
],
"timestamp": "2026-05-19T10:30:00Z"
}
| Field | Description |
|---|---|
allowed | Whether the skill is permitted |
risk_level | Detected risk level: low, medium, or high |
violations | List of policy rules that were violated |
explanation | Human-readable explanation of why the skill was flagged |
top_category | Highest-scoring category across the whole skill (one of 12 VirtueSkillGuard categories) |
top_score | Confidence score of the top category (0.0–1.0) |
sections | Per-section breakdown. Each entry has the markdown heading, line_range, the section's top_category / top_score, and an explanation for that section. |
timestamp | Evaluation timestamp |